
The Straits Times and Wikipedia dominate AI search results for Singapore users
Google, ChatGPT and Perplexity use vastly different sources and framing for the same queries.

As users increasingly turn to chatbots for their information, how does that shape the news and content they are seeing in and about Singapore?
To find out, I ran an experiment using 112 trending search queries (sourced from Google Trends over four weeks) with Google (AI Mode), ChatGPT and Perplexity. By prompting the three most popular AI search engines, I sought to get a sense of what a typical user in Singapore is likely to see.
The short version: For Singapore users, the most commonly cited sources are Wikipedia and The Straits Times.
This experiment used a browser with no browsing history or logins, as well as a VPN setting one’s user location to Singapore, and queries drawn from trending search terms from Google Trends (see methodology below). This experiment analysed the 3,384 source domains cited by the three models (check out this dashboard for an overview).
The data indicates that the AI tools replacing traditional search engines have clearly distinct approaches to what sources they use, and how they present them. For instance, while Google and Perplexity often try to surface locally-specific information unprompted, ChatGPT was much less likely to do so.
Do bear in mind that the results are likely to be different with different queries and testing conditions, and this experiment is more of an initial test than a systematic analysis.
Here are the full results.
Google AI Mode
With Google, The Straits Times was the most frequently cited source – being cited 79 times across 50 distinct queries. With the chatbots used, multiple pages from the same domain were often cited in response to a single query.
The next most-cited sources were Wikipedia (45 queries), Channel News Asia (40 queries), Facebook (38 queries), Instagram (35 queries), and Mothership (26 queries).
Notably, Google AI Mode has a stronger focus on surfacing breaking news and local context, identifying locally-relevant information even when the prompt was generic.
For instance, when the search query was “measles”, Google presented information on the number of confirmed cases in Singapore, while noting that vaccination is compulsory in Singapore. In contrast, ChatGPT presented general information before ending with a line asking if the user might want Singapore-specific information.
Perplexity
In contrast, Perplexity (using its default Sonar model), most frequently cites Wikipedia (56 queries), The Straits Times (39 queries), YouTube (36 queries), and Reddit (32 queries).
Unlike Google, the gap between the most popular news outlet cited (The Straits Times) and the next most popular news outlet cited (Channel News Asia) was larger. CNA was cited in just 25 queries.
ChatGPT
ChatGPT was the one which differed the most from the other two models used. Its most frequently cited sources was Wikipedia (45 queries). News outlets make up a smaller minority of sources used, with Reuters (18 queries) and Channel News Asia (15 queries) being the most frequently cited.
While Google and Perplexity used a median of 14 and 10 sources respectively, ChatGPT used a median of 5 sources per query.
While ChatGPT does list more sources than the ones captured in the analysis, these seem to be largely superficial and does not appear to factor into the text it generates. It is telling that when you use the model’s shareable link function, these additional sources are not displayed (unlike the other models which displayed these additional sources even if they were not cited in the text).
How search engine choice matters
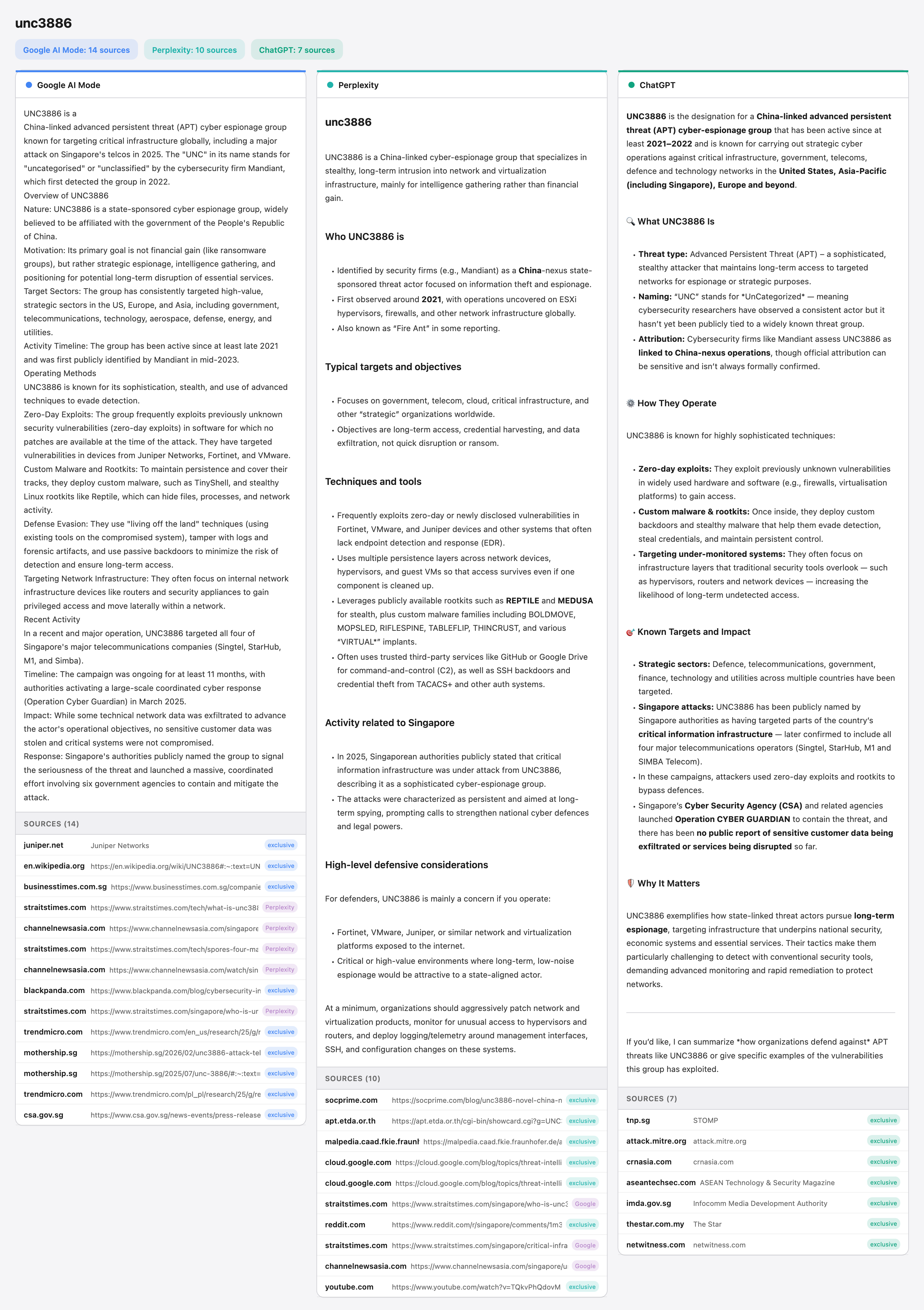
Model choice affects sources used and how they are framed: Even for the same queries, different models took a different approach in selecting what information was relevant to the user.
Of the 1,989 total domain-query pairs, 6.4% of these were surfaced by all three models, and 24.2% were surfaced by at least two models.
The remaining 75.8% are sources that were surfaced by only one of the three models.
This also extends beyond sources used. While Google’s AI Mode places a stronger emphasis on breaking news and recent information, Perplexity and ChatGPT’s responses appear to place a greater emphasis on background information.
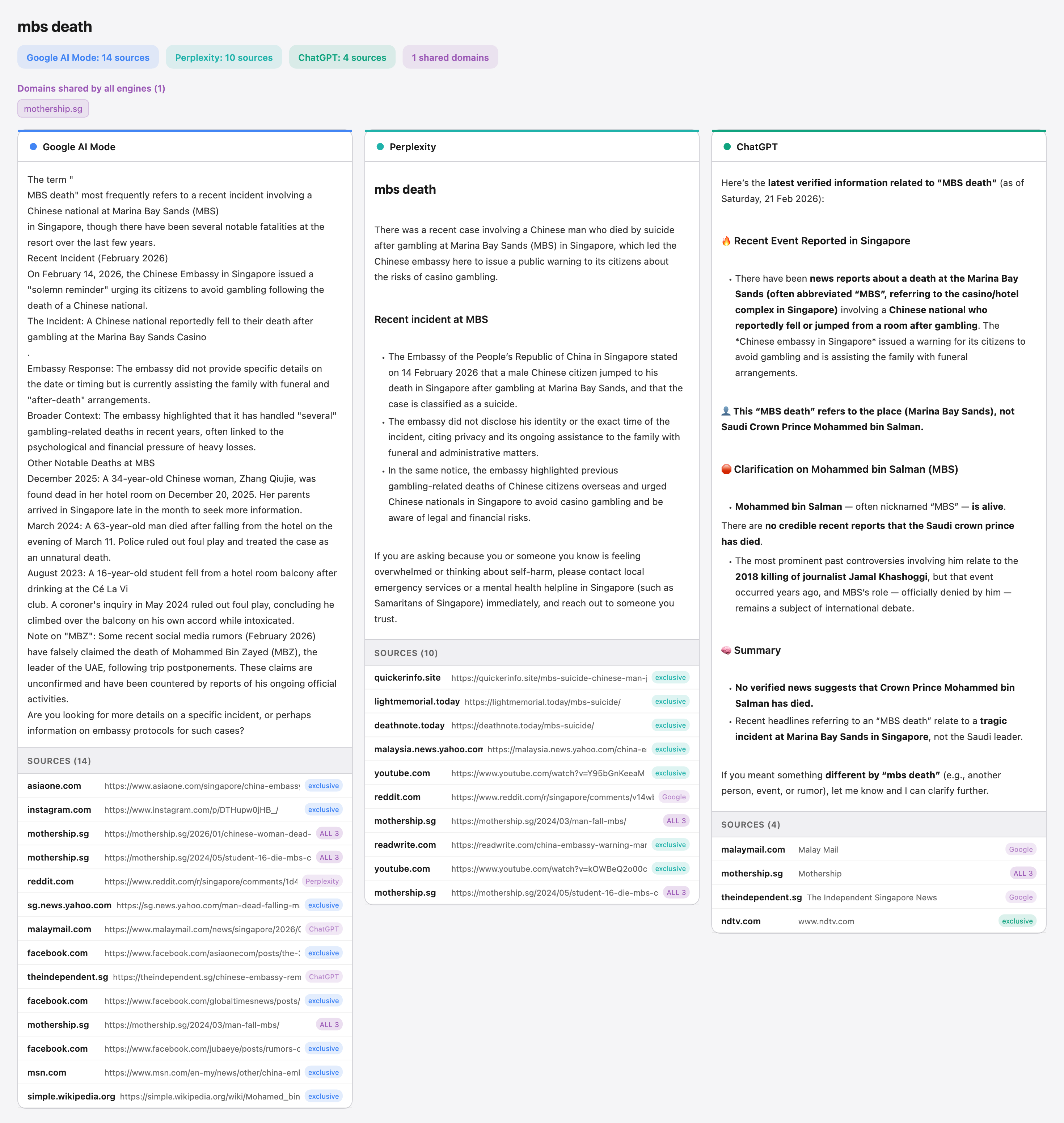
Different models approach user location differently: Even when queries were for subjects totally unrelated to Singapore, Google’s AI Mode and Perplexity would offer (unprompted) information that might be relevant to a Singapore user, often citing local sources even when such topics were not local in nature (like “jeffrey epstein” or “chatgpt caricature”).
With Google and Perplexity, international news outlets were cited far less than local news outlets.
In contrast, ChatGPT appears to prefer surfacing more general information, with user location being less of a factor in its results. It was the only model where an international news outlet (Reuters) was more frequently cited than local ones.
For instance, when the search query was “MBS death”, ChatGPT responded with information on both a recent death from falling at the Marina Bay Sands and the crown prince of Saudi Arabia, Mohammed bin Salman Al Saud (also widely known as MBS).
Key commonalities across models
The majority of sources are only cited for one query: A key commonality from across the search engines is the distribution of sources. The top 5 domains on all models used accounted for between 20% and 23% of all sources used.
Most domains are cited for only a single query, something that is obscured by only looking at the most frequently cited sources. All three models generally seek out specific sources, even though encyclopedias (Wikipedia, Encyclopedia Britannica) and mainstream media outlets are often cited.
Models prioritise mainstream media sources: All three models appear to prioritise mainstream (local and international) media outlets.
TheSmartLocal was the most frequently cited non-mainstream outlet, appearing in just 10 queries across all three models. The next most-cited are The Online Citizen (9 queries), The Independent Singapore (8 queries), and MustShareNews (5 queries).
The representation of mainstream media outlets is likely to be higher than the data indicates, as many social media sources cited (Reddit, Facebook, Instagram, YouTube) are links to pages discussing mainstream media articles.
Methodology
If you’re curious to play around with the dataset, check out this dashboard compiling all the queries and the output each model gave in response.
I was inspired by the Institute for Public Policy Research (IPPR) running an experiment on what kinds of news sources are being cited by the most popular chatbots in the UK – which found that certain chatbots favoured certain news sources.
While the IPPR tested four AI tools’ performance across 100 randomly generated news queries, I opted to go for a more targeted approach, focusing on popular search terms in Singapore in the period spanning 25 January to 22 February (or around four weeks).
The queries I used are a selection of terms sourced from Google Trends, with each racking up at least 1,000 searches by Singapore users in the seven-day cycles for which trending data is available.
I excluded sports-related terms (which form the vast majority of all Google Trends’ trending search terms), and where there were multiple similar terms, I opted for the one with greater specificity. For instance, “muis ramadan 2026” over “ramadan”.
While past experiments have sought to prompt chatbots multiple times, as it often provides different results each time, I thought doing single queries was enough for an initial analysis while limiting environmental impact. Each query was made using a browser without any browsing history or login, with a VPN active and a location set to Singapore.